Complete Lesson on SS Total Anova Calculator
In functioning to absorb what is all had in an ANOVA table, allow’s start with the column headings. And understand more about the ss total ANOVA calculator.
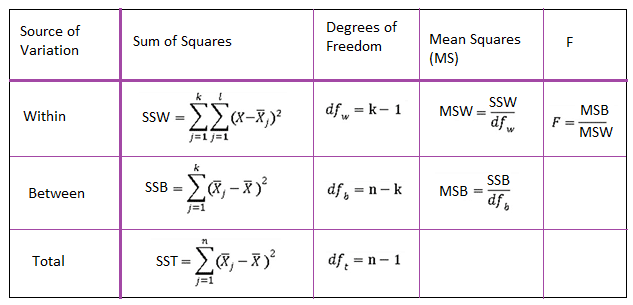
The source indicates “the source of the variant in the data.” As we’ll soon witness, the feasible choices for one-factor research, such as the understanding study, are Variable, Error, as well as Total. The element is the characteristic that specifies the populaces being contrasted. In the tire research study, the factor is the brand name of a tire. In the knowing research, the variable is the understanding technique.
DF implies “the levels of liberty in the source.”
SS implies “the sum of squares to the source.”
MS implies “the mean sum of squares because of the resource.”
F implies “the F-statistic.”
P indicates “the P-value.”
Currently, let’s think about the row headings:
Variable indicates “the variability as a result of the aspect of passion.” In the tire instance on the previous page, the element was the brand of the tire. In the discovering example on the previous web page, the element was the method of learning.
In some cases, the aspect is a therapy, and also consequently, the row heading is instead labeled as Therapy. Sometimes, the row heading is classified as Between to make it clear that the row worries the variation in between the teams.
Mistake indicates “the variability within the groups” or “unexplained random mistake.” Often, the row heading is classified as Within to clarify that the row concerns the variant within the groups.
Complete ways “the overall variant in the information from the grand mean” (that is, ignoring the variable of interest).
Understanding more about ss total ANOVA calculator
Let’s work our means with it entry by the entrance to see if we can make it the green light. Let’s start with the levels of freedom (DF) column:
If there are n overall data points collected, then there is n − 1 total degree of freedom.
Also, If m teams are being compared, then there is m − 1 level of freedom related to the factor of passion.
If there are n general information points accumulated and m groups being contrasted, then there are n − m error degrees of flexibility.
Currently, the numbers of squares (SS) column:
As we’ll soon formalize below, SS( In Between) is the number of squares between the group suggests and the grand mean. As the name recommends, it evaluates the irregularity in between the teams of passion.
Once again, as we’ll formalize below, SS( Error) is the sum of squares in between the data and the team suggests. It evaluates the variability within the groups of the rate of interest.
SS( Complete) is the number of squares between the n information points and the grand mean. As the name recommends, it evaluates the total variability in the observed information. We’ll soon see that the overall number of squares, SS( Overall), can be gotten by adding the between the number of squares, SS( Between), to the error number of squares, SS( Error). That is:
SS( Overall) = SS( Between) + SS( Error).
The mean squares (MS) column, as the name suggests, contains the “average” number of squares for the Variable as well as the Mistake.
The Mean number of Squares between the teams, denoted MSB, is calculated by dividing the Number of Squares between the teams by the in-between group degrees of flexibility. That is, MSB = SS( Between)/( m − 1).
The Error Mean Sum of Squares, signified MSE, is determined by splitting the Sum of Squares within the groups by the error levels of liberty. That is, MSE = SS( Error)/( nm).
Final Note
The F column, not remarkably, contains the F-statistic. Since we want to contrast the “ordinary” irregularity between the teams to the “ordinary” abnormality within the groups. We consider the ratio of the In-between Mean Amount of Squares to the Mistake Mean Sum of Squares. That is, the F-statistic is calculated as F = MSB/MSE.
When we explore the concept behind the analysis of variance approach on the next blog. We’ll see that the F-statistic complies with an F-distribution with m − 1. Numerator degrees of flexibility and n − m levels of flexibility. Therefore, we’ll determine the P-value, as it appears in the column labeled P. By comparing the F-statistic to an F-distribution with m − 1 numerator levels of liberty. As well as n − m common denominator degrees of flexibility.



